td-spark API Documentation
td-spark is a library for reading and writing tables in Treasure Data through the DataFrame API of Apache Spark. For Python users, td-pyspark PyPI package for PySpark is available.
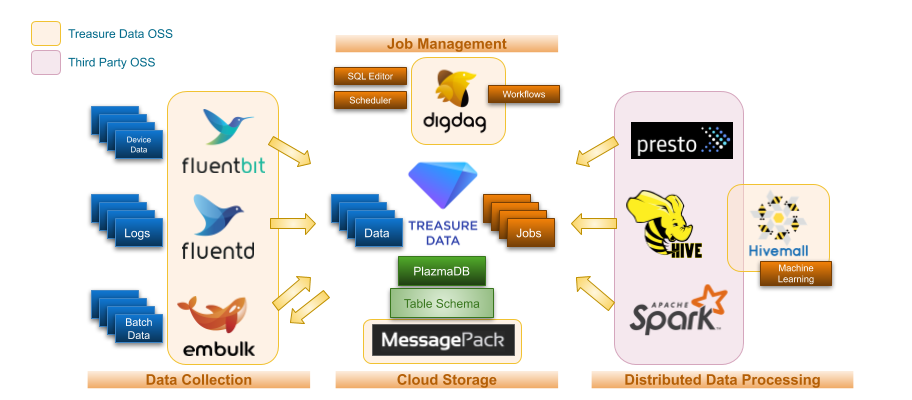
Features
td-spark supports:
Reading and writing tables in TD through DataFrames of Spark.
Running Spark SQL queries against DataFrames.
Submitting Presto/Hive SQL queries to TD and reading the query results as DataFrames.
If you are using PySpark, you can use both Spark’s DataFrames and Pandas DataFrames interchangeably.
Using any hosted Spark services, such as Amazon EMR, Databrics Cloud. - It’s also possible to use Google Colaboratory to run PySpark.
Download & Release Notes
td-spark (Scala)